Publications
These are my publications.
2024
-
 The Vulnerable Identities Recognition Corpus (VIRC) for Hate Speech AnalysisIbai Guillén-Pacho, Arianna Longo, Marco Antonio Stranisci, and 2 more authorsIn Proceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024) , Dec 2024
The Vulnerable Identities Recognition Corpus (VIRC) for Hate Speech AnalysisIbai Guillén-Pacho, Arianna Longo, Marco Antonio Stranisci, and 2 more authorsIn Proceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024) , Dec 2024This paper presents the Vulnerable Identities Recognition Corpus (VIRC), a novel resource designed to enhance hate speech analysis in Italian and Spanish news headlines. VIRC comprises 921 headlines, manually annotated for vulnerable identities, dangerous discourse, derogatory expressions, and entities. Our experiments reveal that large language models (LLMs) struggle significantly with the fine-grained identification of these elements, underscoring the complexity of detecting hate speech. VIRC stands out as the first resource of its kind in these languages, offering a richer annotation schema compared to existing corpora. The insights derived from VIRC can inform the development of sophisticated detection tools and the creation of policies and regulations to combat hate speech on social media, promoting a safer online environment. Future work will focus on expanding the corpus and refining annotation guidelines to further enhance its comprehensiveness and reliability.
-
 PODIO: A Political Discourse OntologyIbai Guillén-Pacho, Ana Iglesias-Molina, Carlos Badenes-Olmedo, and 1 more authorNov 2024
PODIO: A Political Discourse OntologyIbai Guillén-Pacho, Ana Iglesias-Molina, Carlos Badenes-Olmedo, and 1 more authorNov 2024In this study, we present the POlitical DIscourse Ontology (PODIO) and the accompanying Knowledge Graph, both designed to enhance the formalization and accessibility of political discourse in digital media. The core contribution of this work is the development of a comprehensive ontological framework and its instantiation in a Knowledge Graph that systematically organizes and represents political discourse. This framework provides structured insights to better understand and analyze political debates on various digital platforms. PODIO is specifically engineered to address the complexities of political communication, enabling detailed analysis of political proposals, ideological foundations, target audiences, and the temporal context of discourse. Through the integration of diverse existing datasets into the Knowledge Graph, we demonstrate PODIO’s effectiveness in encapsulating a broad spectrum of semantically annotated political discourses
-
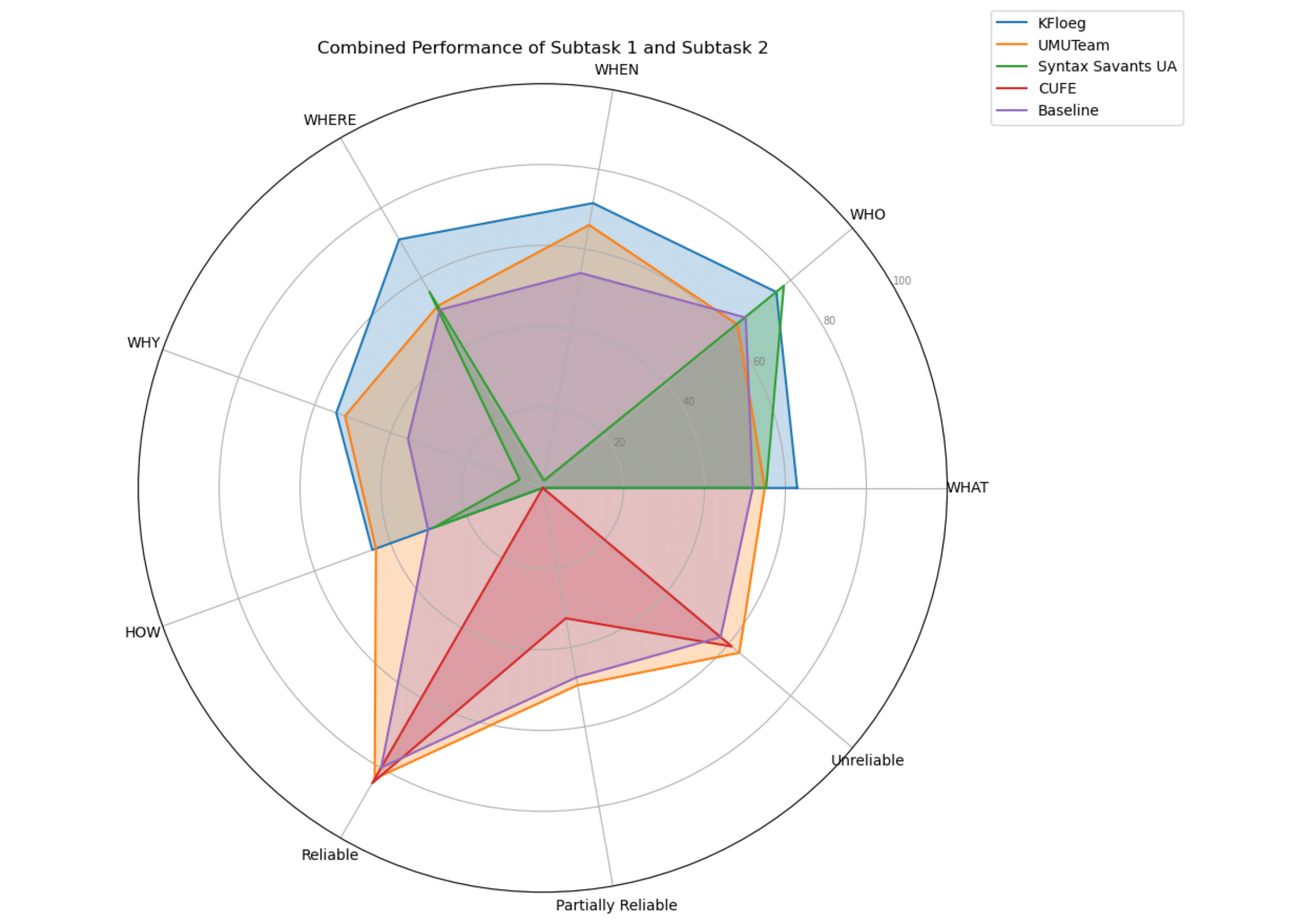 Overview of FLARES at IberLEF 2024: Fine-grained Language-based Reliability Detection in Spanish NewsRobiert Sepúlveda-Torres, Alba Bonet-Jover, Isam Diab, and 7 more authorsProcesamiento del Lenguaje Natural, Sep 2024
Overview of FLARES at IberLEF 2024: Fine-grained Language-based Reliability Detection in Spanish NewsRobiert Sepúlveda-Torres, Alba Bonet-Jover, Isam Diab, and 7 more authorsProcesamiento del Lenguaje Natural, Sep 2024This paper presents FLARES, a shared task organised in the framework of the evaluation campaign of Natural Language Processing systems in Spanish and other Iberian languages, IberLEF 2024. FLARES aims to detect patterns of reliability in the language used in news that will allow the development of effective techniques for the future detection of misleading information. To this end, the 5W1H journalistic technique for detecting the relevant content of a news item is proposed as a basis, as well as an annotation guideline designed to detect linguistic reliability. Two subtasks are proposed: the first focusing on the identification of the 5W1H elements and the second focusing on the detection of reliability. A total of 7 participants registered in the shared task, of which 3 participated in the first subtask and 4 in the second. The teams proposed various approaches, especially based on fine-tuning of encoding models and adjustment of instructions in decoding models.
-
 Leveraging Temporal Analysis to Predict the Impact of Political Messages on Social Media in SpanishIbai Guillén-PachoIn NLP-DS@SEPLN , Sep 2024
Leveraging Temporal Analysis to Predict the Impact of Political Messages on Social Media in SpanishIbai Guillén-PachoIn NLP-DS@SEPLN , Sep 2024Social networks such as TikTok, Facebook, or X introduce techniques to inform users if the content they are consuming may be fake. This, together with the account banning for hate speech or disinformation spread, is leading more and more pseudo-media in Spain to use Telegram to communicate with their audience. Thus, it is difficult to warn users about the veracity of the content, leading them to accept political disinformation as true if it aligns with their beliefs, which ultimately promotes their polarization. In this work, we want to identify the political messages that will have the greatest impact on people to recommend when it is necessary to initiate a refutation strategy if it is disinformative, so that refutation begins before disinformation is taken as true by a part of society. To estimate the impact of political messages, we take into account the polarization generated by them and their virality. Our main hypothesis is that this value is proportional to the time of publication, with the greatest impact in the most politically and socially sensitive contexts. Hence, our goal is to compile a dataset of political messages disseminated on Telegram (along with the generated responses) and its temporal context, in order to develop methods and metrics to identify the expected impact and when they might have the greatest impact.
-
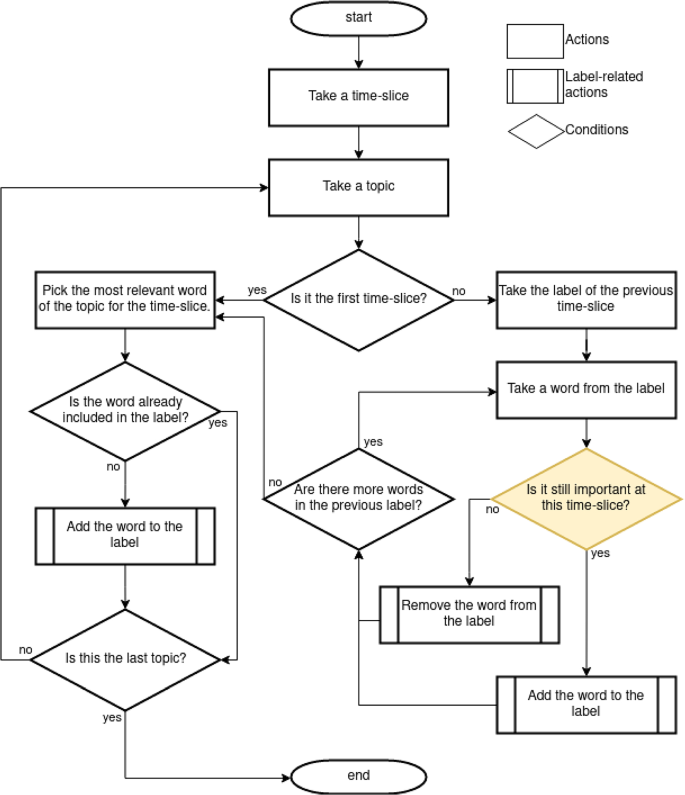 Dynamic topic modelling for exploring the scientific literature on coronavirus: an unsupervised labelling techniqueIbai Guillén-Pacho, Carlos Badenes-Olmedo, and Oscar CorchoInternational Journal of Data Science and Analytics, Aug 2024
Dynamic topic modelling for exploring the scientific literature on coronavirus: an unsupervised labelling techniqueIbai Guillén-Pacho, Carlos Badenes-Olmedo, and Oscar CorchoInternational Journal of Data Science and Analytics, Aug 2024The work presented in this article focusses on improving the interpretability of probabilistic topic models created from a large collection of scientific documents that evolve over time. Several time-dependent approaches based on topic models were compared to analyse the annual evolution of latent concepts in the CORD-19 corpus: Dynamic Topic Model, Dynamic Embedded Topic Model, and BERTopic. Then COVID-19 period (December 2019–present) has been analysed in greater depth, month by month, to explore the evolution of what is written about the disease. The evaluations suggest that the Dynamic Topic Model is the best choice to analyse the CORD-19 corpus. A novel topic labelling strategy is proposed for dynamic topic models to analyse the evolution of latent concepts. It incorporates content changes in both the annual evolution of the corpus and the monthly evolution of the COVID-19 disease. The generated labels are manually validated using two approaches: through the most relevant documents on the topic and through the documents that share the most semantically similar label topics. The labelling enables the interpretation of topics. The novel method for dynamic topic labelling fits the content of each topic and supports the semantics of the topics.





2022

2021
-
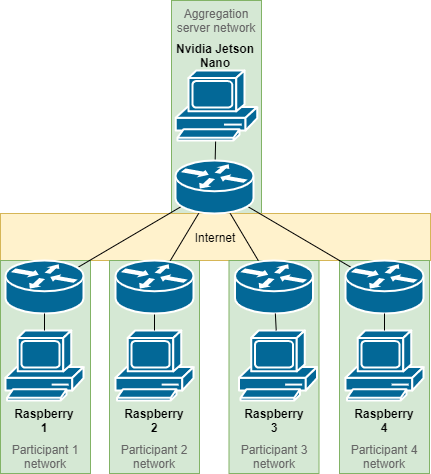 A Recommender System that safeguards the user privacy through Federated LearningIbai Guillén-Pacho, Rubén Sánchez-Corcuera, and Diego Casado-MansillaIn 2021 6th International Conference on Smart and Sustainable Technologies (SpliTech) , Oct 2021
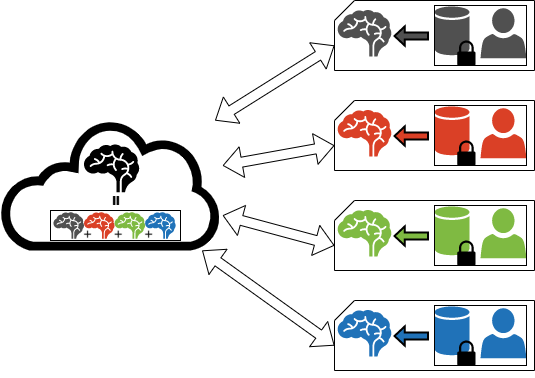
A Recommender System that safeguards the user privacy through Federated LearningIbai Guillén-Pacho, Rubén Sánchez-Corcuera, and Diego Casado-MansillaIn 2021 6th International Conference on Smart and Sustainable Technologies (SpliTech) , Oct 2021Nowadays, there are more and more legal and ethical limitations when it comes to managing personal data. This is a serious problem for recommender systems (RS) or similar aplications since personal data (e.g. socioeconomic, demographics, behavioural, etc.) are the most useful for generating tailored correlations and predictions. To cope with this issue, this work proposes a recommender system that safeguards the user privacy by using a Federated Learning approach (FL). To this end, this article takes as the baseline an already existing centralized RS that uses all the data from users in a clear manner. This baseline RS is based on Factor Machines and it aims to employ persuasion strategies adapted to the user to increase energy awareness and change their consumption habits in the work environment. In order to test the performance of the FL-based distributed RS, the real dataset used (N=678) have been separated into four subsets mimicking a segmentation by country of origin (Austria, UK, Spain and Greece). Each country can create an artificial intelligence model suitable for its users that will be sent to a central server where the aggregation of models will take place and the improved global model will be returned back to each country. The simulation of this FL strategy is performed with four Raspberry Pi’s reflecting each country and an NVIDIA Jetson Nano is used as the aggregation server. The generated model not only increases the privacy of the users as no raw data travels to the central server but also improves the reliability of the recommendations.
-
 Estudio sobre la privacidad en el aprendizaje federado mediante el desarrollo de un sistema de recomendación onlineIbai Guillén-PachoJul 2021
Estudio sobre la privacidad en el aprendizaje federado mediante el desarrollo de un sistema de recomendación onlineIbai Guillén-PachoJul 2021Este proyecto final de grado presenta un estudio sobre la privacidad en el aprendizaje federado mediante el desarrollo de un sistema de recomendación. El sistema de recomendación de estrategias de persuasión parte del proyecto de R. Sánchez y col. y será modificado para operar de forma descentralizada en varios dispositivos. Cada dispositivo elaborará su propio modelo de inteligencia artificial con sus datos. Mediante el protocolo de Federated Learning los modelos de inteligencia artificial de los distintos dispositivos serán combinados para mejorar su precisión en las recomendaciones. El enfoque de agregación de los modelos de inteligencia artificial será interpretado de forma diferente al canónico Federated Learning, en este proyecto se abordará el tema de la agregación desde el reentrenado de los modelos con información sintética, evitando así, compartir información sensible de los dispositivos.El estudio analizará el rendimiento del sistema de recomendación funcionando sobre aprendizaje automático de forma centralizada, es decir con toda la información disponible, así como el rendimiento del mismo sistema con información distribuida, tanto antes como después de ser agregada en el servidor de Federated Learning. De esta forma, se podrán observar las ventajas de la segregación de información y el impacto del Federated Learning en los modelos de los participantes, tanto a nivel de rendimiento como de mejora de la privacidad.El estudio y los experimentos se realizarán sobre una red real, creada sobre un entorno de desarrollo basado en varias Raspberries Pi (para representar a los participantes de la red de Federated Learning) y una NVIDIA Jetson Nano (como servidor central para agregar los modelos).


2020
-
 Blockchain-mediated Collaboration of Citizens in Open Government ProcessesMikel Emaldi, Koldo Zabaleta, Ibai Guillén-Pacho, and 1 more authorIn 2020 5th International Conference on Smart and Sustainable Technologies (SpliTech) , Jul 2020
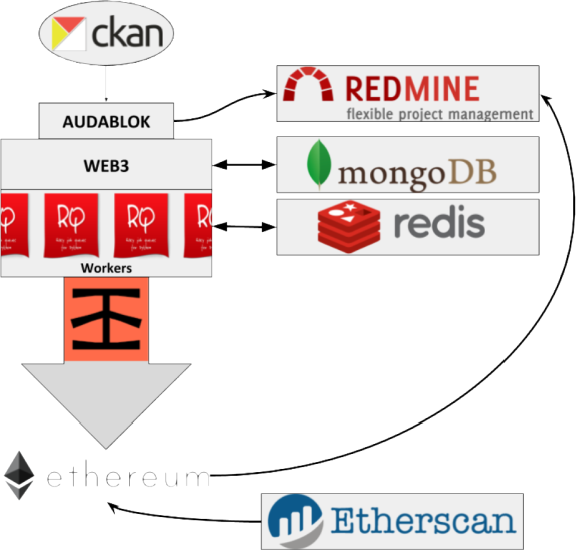
Blockchain-mediated Collaboration of Citizens in Open Government ProcessesMikel Emaldi, Koldo Zabaleta, Ibai Guillén-Pacho, and 1 more authorIn 2020 5th International Conference on Smart and Sustainable Technologies (SpliTech) , Jul 2020This work explores how sustainable citizen collaboration to foster Open Government can be achieved by means of Blockchain-based solution. The technical feasibility and economic viability of a set of extensions of CKAN tool, bringing together Internet of People (IoP) related technologies such as Blockchain and crowdsourcing, to address sustainability in Open Government Portals is analysed. For that, a use case validation is performed, and the costs of its deployment assessed. The aim is to show how IoP promoting technologies enhance Public Administration (PA) and citizen collaboration to meet common interest objectives.
